Primary Tools
Python, FastAI, Gradio, HuggingFace

Hefner Museum of Natural History
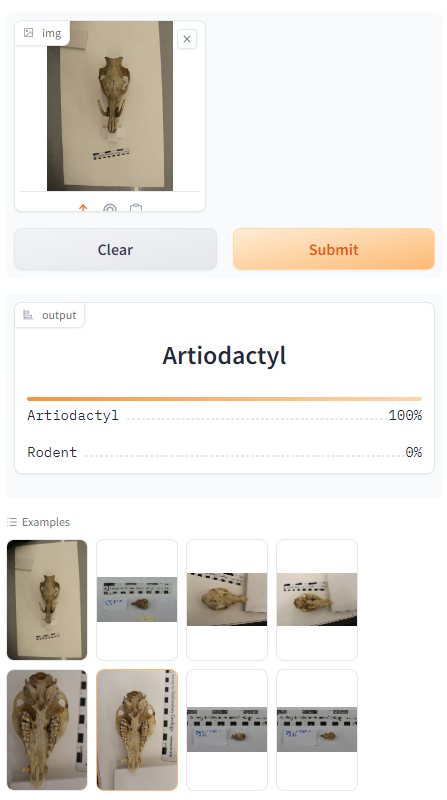
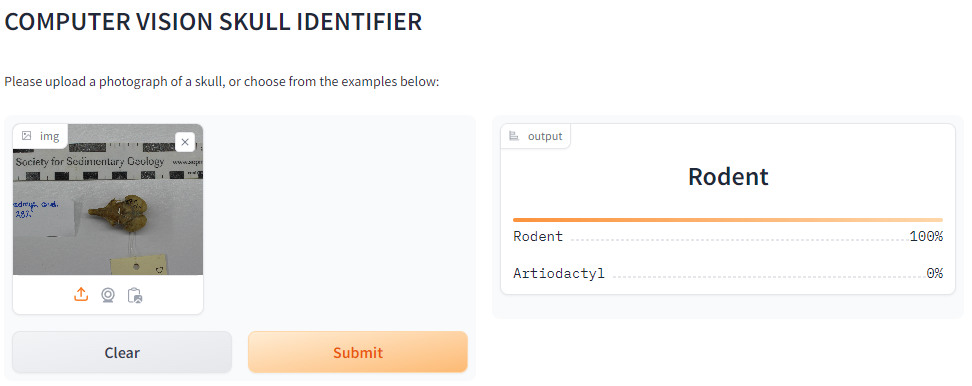
Use AI to streamline the identification of museum specimens (mammal skulls) from photographs.
Python, FastAI, Gradio, HuggingFace
The client serves as a physical repository for tens of thousands of museum specimens, including hundreds of mammal skulls. These skulls occupy a large amount of physical space and pose unique storage challenges for the client. The client requires a solution for quickly identifying the type of skull in order to streamline its association with the relevant digital metadata.
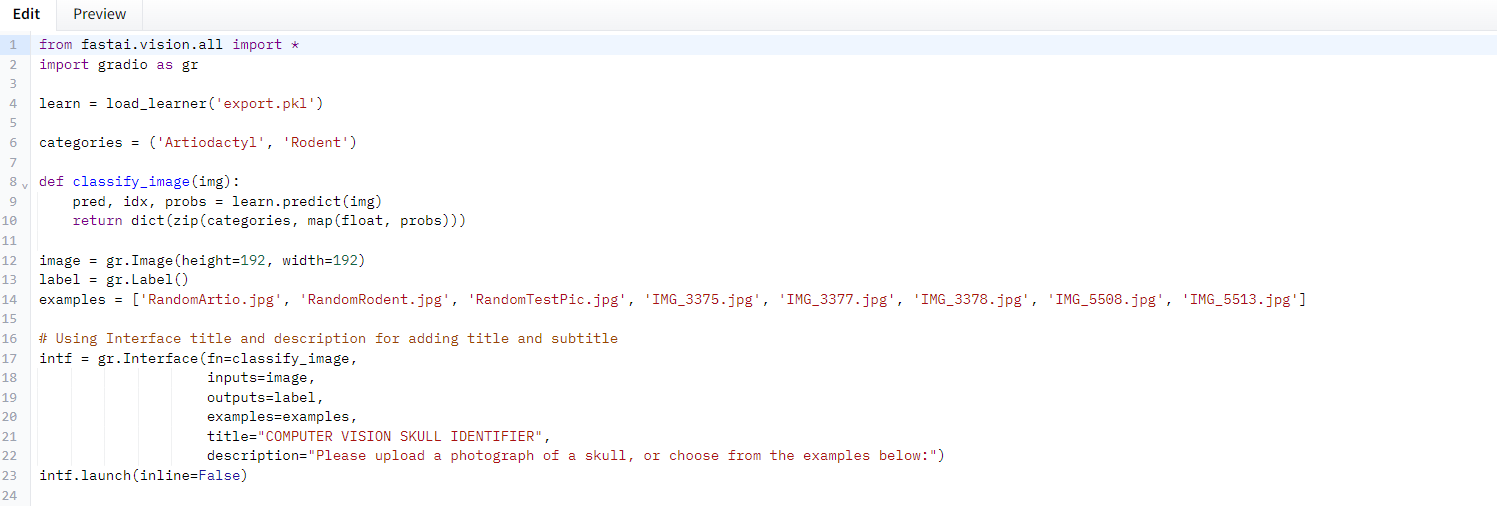
###Product Our team developed a working prototype of a computer vision model powered by AI. The model received user input (photographs of mammal skulls) and correctly classifies them into mammalian Orders.